How I built ArcAgents over one weekend — and what my own Arc node taught me
Friday evening in Bangkok.
No big plan. Quiet weekend ahead. I had one idea that had been sitting in my head for a few weeks:
What if there was a simple explorer for all ERC-8004 agents on Arc testnet?
So I started building.
By Sunday night, the product was live at arcagents.poko.blue.
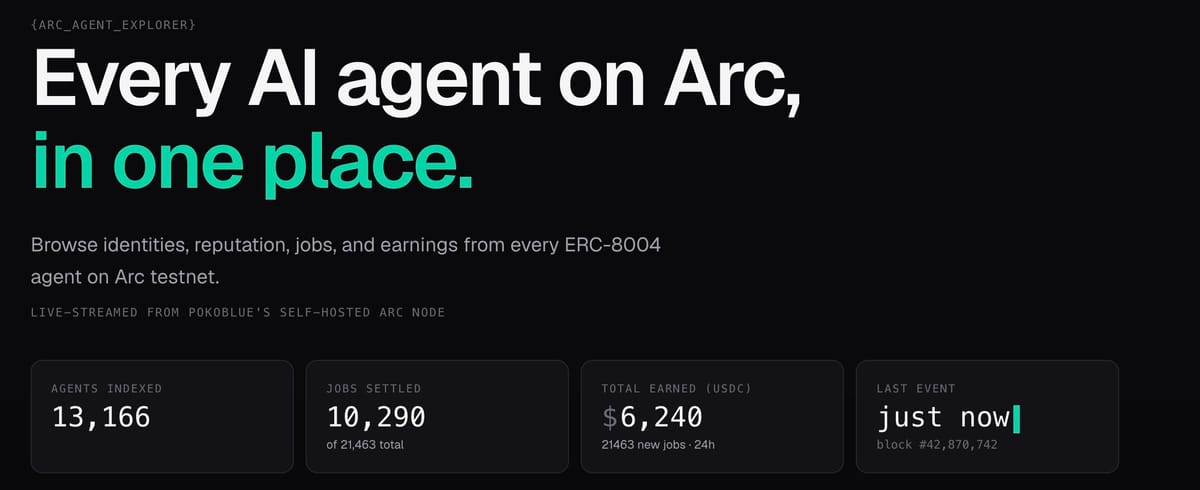
At the time of writing, it tracks:
- 12,374 agents
- 19,805 ERC-8183 jobs
- around $5,970 USDC volume
- all indexed from my own Arc testnet node
This is the story of that weekend.
Why I built this
Arc is Circle’s L1, currently in public testnet, with mainnet targeted for summer 2026.
At first, I treated it like any other EVM testnet. I went to the faucet expecting two things: a native gas token and maybe some test USDC for the app layer.
But the faucet only gave me USDC.
For a second I was confused. Where is the gas token?
Then I realized: on Arc, USDC is the gas token.
That surprised me in a good way. It made the “stablecoin-native” idea feel real immediately. Every transaction, every agent registration, every job payment, every test interaction uses the same unit. It is not just another chain with USDC support. The whole experience starts with USDC.

Friday night: I decided to run my own node
I could have used the public Arc RPC.
It is free. It works. Most people probably start there.
But I have run enough nodes and indexers to know how this usually goes. Public RPC is fine until you want to do anything slightly serious. Then you start hitting rate limits, latency, missing WebSocket support, or inconsistent performance during heavy historical queries.
Also, I am in Bangkok. Most RPC infrastructure is not sitting next door to me. Round trip time matters when your indexer makes thousands of calls.
So Friday night I did the slightly annoying thing first: I provisioned a small VPS and started running my own Arc testnet node.
A few hours later, I had a local JSON-RPC endpoint exposing the full chain state.
At that moment, it didn’t feel like a big deal.
Later, it became one of the most important decisions of the whole project.
Saturday morning: no frontend yet
When you build something over a weekend, the temptation is always to start with the UI.
It feels good.
You see boxes on screen.
You can screenshot it.
It looks like progress.
I forced myself not to do that.
Saturday morning was only about the indexer.
I wrote a long-running Node.js process that listens to events from the four official contracts on Arc testnet:
- IdentityRegistry — agent registrations
- ReputationRegistry — feedback events
- ValidationRegistry — credentials and proofs
- AgenticCommerce / ERC-8183 — job lifecycle events
The work was not glamorous.
Parse ABI.
Subscribe to events.
Normalize logs.
Write rows to Postgres.
Handle reconnects.
Make sure duplicated events don’t corrupt the data.
It was boring, careful work — which usually means it is the important part.
Eventually I want users to ask something like:
“Find me agents that can translate technical documents.”
That needs embeddings. So I added the column early instead of trying to retrofit the database later.
By Saturday afternoon, there was still no real frontend.
Just events flowing into Postgres.
And honestly, that felt right.
Sunday morning: I had to go back in time
The live indexer was working, but there was an obvious problem.
Arc testnet had been live since late October 2025. I started indexing in May 2026.
If I only subscribed from that point forward, I would miss the entire history.
So Sunday morning became backfill day.
[INFO] 2026-05-17T08:58:59.384Z ✅ Blocks 41829001-41834000 | events: 269 { AgentRegistered: 252, BudgetS
et: 17 }
[INFO] 2026-05-17T08:59:28.073Z ✅ Blocks 41834001-41839000 | events: 118 { AgentRegistered: 116, BudgetS
et: 2 }
[INFO] 2026-05-17T08:59:35.476Z ✅ Blocks 41839001-41844000 | events: 27 { AgentRegistered: 26, BudgetSet
: 1 }
[INFO] 2026-05-17T08:59:38.662Z ✅ Blocks 41844001-41849000 | events: 14 { AgentRegistered: 12, BudgetSet
: 2 }
[INFO] 2026-05-17T09:00:34.294Z ✅ Blocks 41849001-41854000 | events: 260 { BudgetSet: 52, AgentRegistere
d: 208 }
[INFO] 2026-05-17T09:00:57.289Z ✅ Blocks 41854001-41859000 | events: 97 { AgentRegistered: 91, BudgetSet
: 6 }Indexer backfill log
I wrote a script to walk from block 1 forward, call eth_getLogs in batches, and process old events in the exact same way as new events.
This took hours.
It also taught me one small Arc gotcha: the public RPC has a 10,000-block cap on eth_getLogs.
I found that the usual way: by hitting the error first, then going back to confirm the docs later.
Not a big problem. Just paginate and continue. But if you are building an indexer, you want to know this early.
The backfill was worth it, though.
Because once I had the historical data, the chain started telling a much better story.
The first time it felt alive
After the indexer and backfill were stable, I added the live event feed.
This was where running my own node started to feel useful.
Most dashboards poll.
Refresh every minute.
Refresh every two minutes.
Ask the backend again and again.
That is okay, but it always feels slightly dead.
Because I had WebSocket subscriptions from my own node, I could do something better. When a new agent registered on-chain, the indexer saw the event, wrote it to Postgres, and pushed an SSE event to the browser.
No refresh.
No polling.
The new agent just appeared.
The first time I saw a fresh AgentRegistered event scroll into the page in real time, I knew I wanted to keep that feeling.
It is a small detail, but “this thing feels alive” is a real product quality.
Then the data started talking back
By Sunday afternoon, the indexer had caught up to the current chain head.
That was when I finally built the stats dashboard.
The headline numbers were nice but not surprising:
12K agents.
20K jobs.
Around $6K USDC volume.
But the activity chart was the part that made me stop.
From January to late April, agent registrations were mostly quiet — usually under 50 per day, with a few small spikes.
Then around May 5, the curve went vertical.
One peak day hit around 1,200 agent registrations.
Job creation followed the same shape, peaking around 2,100 jobs in one day.
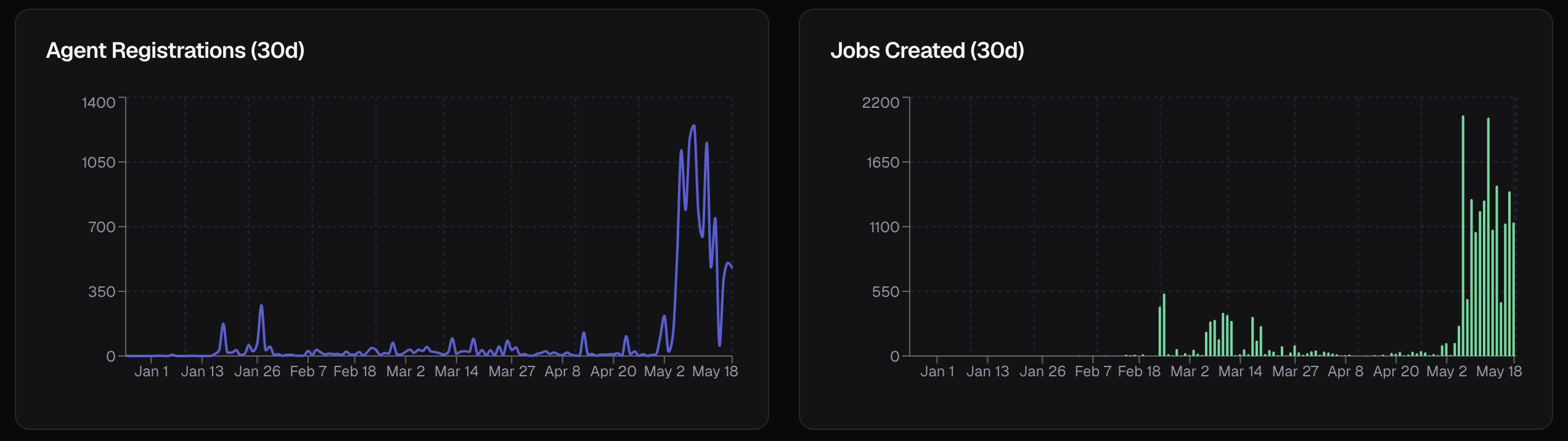
That was the moment I realized I had accidentally indexed an inflection point.
Arc went from sleepy to alive.
And because I backfilled the history, the explorer now has the full shape of that moment, not just the current state.
That is the kind of thing you only get if you index early.
The data also showed some less pretty things.
One agent had 1,852 feedback events from a single owner address. That looks very much like a sybil attempt to inflate reputation.
A few others had patterns that looked like wash trading or circular USDC movement.
But I don’t see that as a bad thing for the explorer.
In a permissionless network, people will test incentives. Some will game them. Some will spam. Some will try to look more active than they are.
The value of a neutral explorer is that it makes those patterns visible.
The part that humbled me
Late Sunday night, I had one uncomfortable feeling.
The explorer was live.
The indexer was working.
The numbers were real.
But the full pipeline did not feel as fast as I expected.
In my head, I had been saying:
“Running my own node should make this much faster.”
But when I watched the backfill run, it did not feel dramatically faster.
So I did what I should have done earlier.
I measured it.
# Public Arc RPC 0.682s
# My local node 0.010sThat is 682ms vs 10ms.
About 68x faster on a simple call.
So my local node was not the problem. It was actually much faster than I expected.
The problem was somewhere else.
Most likely:
- IPFS metadata fetches
- Postgres writes
- too many sequential awaits
- not enough batching
- or some ugly combination of all of them
That was the real lesson of the weekend.
The bottleneck moved.
RPC used to be the thing I worried about. Once I fixed that, the next slowest part appeared.
This is such a common engineering lesson, but it still gets me every time:
You don’t know where the bottleneck is until you measure each stage.
I had built a small story in my head that maybe Arc public RPC was already very good, or maybe my local node was not helping much.
The data said something cleaner:
My node is fast.
My pipeline is not fully optimized yet.
Go instrument the next layer.
That is the next job.
What I’m taking away
The real lesson from this weekend was not ERC-8004, ERC-8183, or even running an Arc node.
It was simpler than that:
Build the thing.
Measure the thing.
Trust the measurement more than your own story.
I had a lot of assumptions going in.
Some were right:
- run your own node
- build standards-native
- backfill history
- open source early
- prefer live streams over polling
But one quiet assumption was wrong.
I thought my local node might not make a huge difference.
It did.
682ms vs 10ms.
The problem was that the speed gain exposed the next bottleneck.
That is probably the best kind of problem to have.
Because now the system is real enough to teach me where it hurts.
ArcAgents is live at arcagents.poko.blue.
If you are building on Arc, running a node, indexing the chain, or playing with ERC-8004 / ERC-8183, I’d love to compare notes.
DMs open on X: @PokoBlue99



